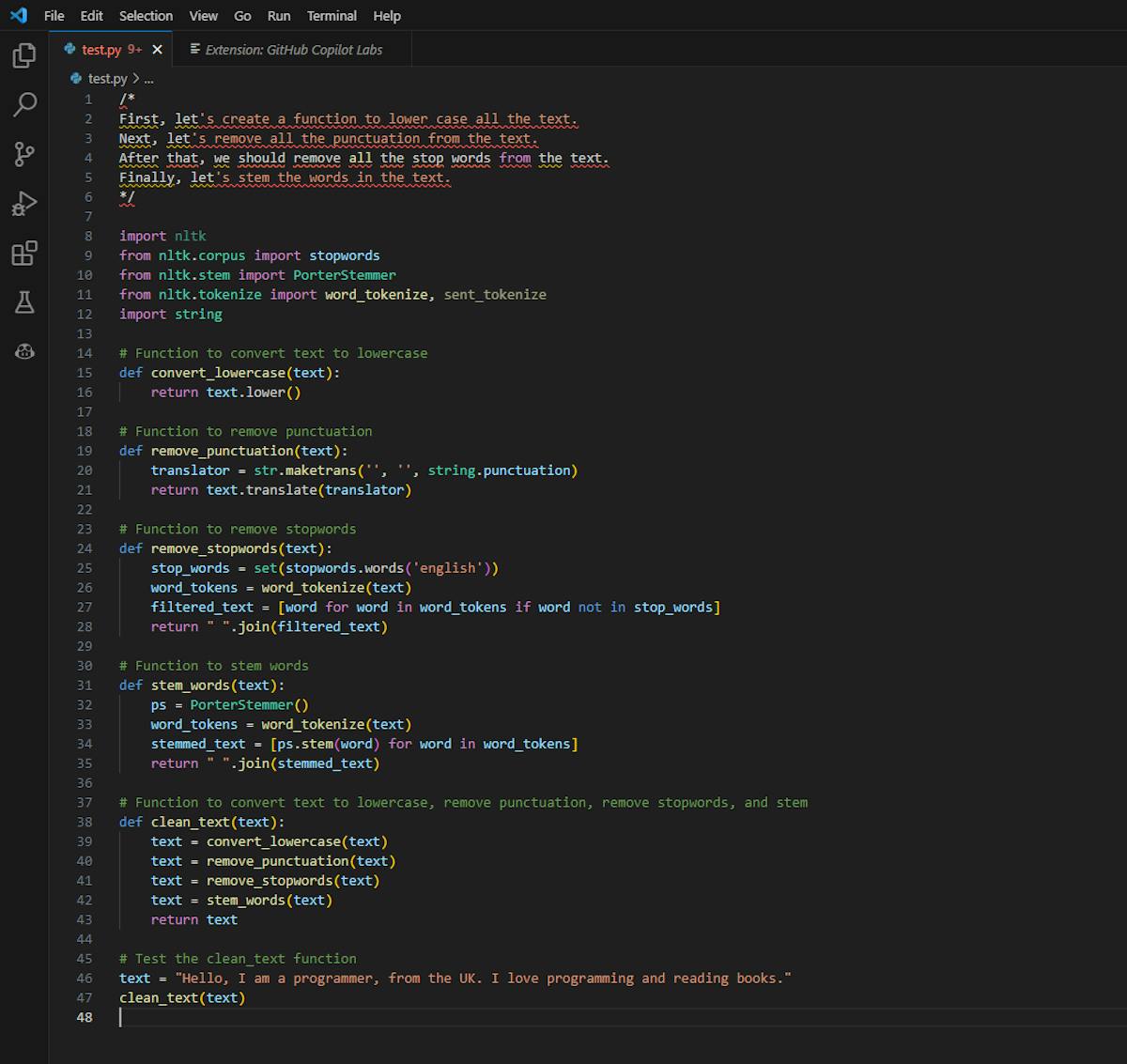
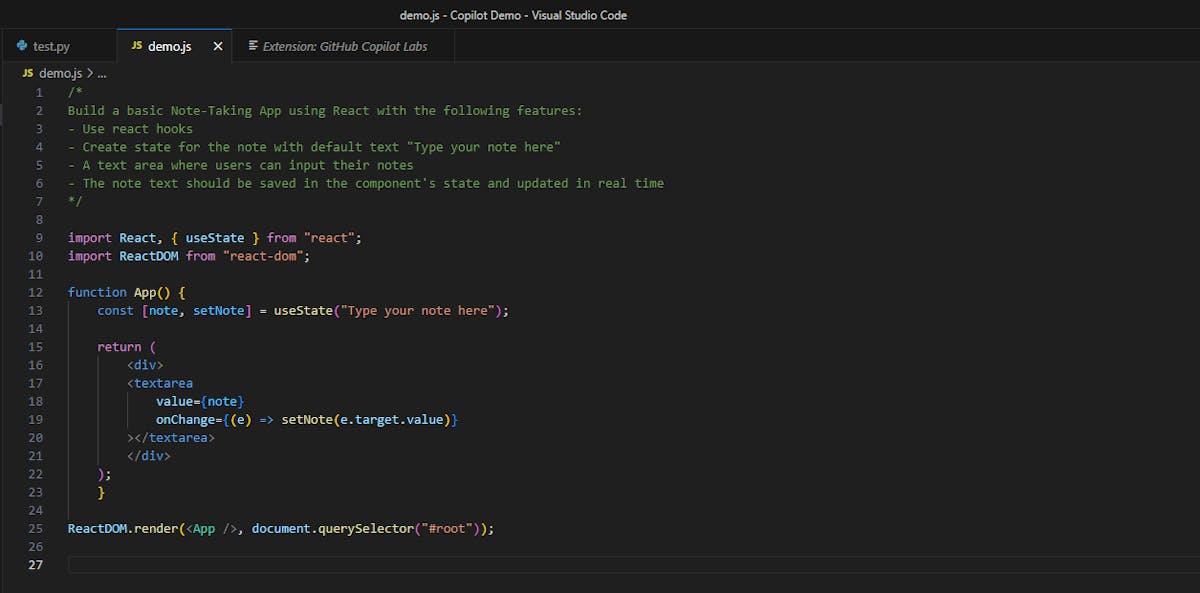
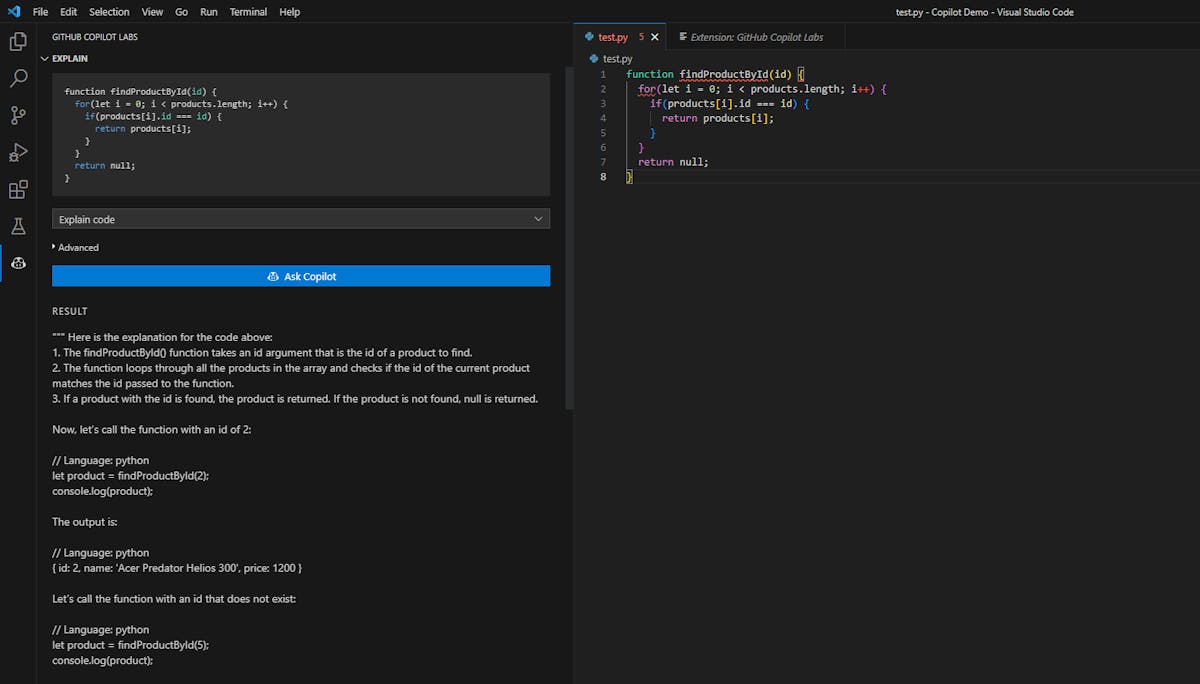
For instance, when you're developing a markdown editor using Next.js, a detailed comment specifying your goals helps GitHub Copilot understand what you're trying to achieve. This might include the intended features, the state for markdown, how the users will interact with the application, etc. The more explicit you are with your instructions, the more tailored the code GitHub Copilot generates will be.
For more detailed information on the functionalities and capabilities of GitHub Copilot, you may refer to this comprehensive guide by Hatica here. Similarly, for insights into other AI-based coding assistance tools such as Amazon CodeGuru, also known as CodeWhisperer, this Hatica article provides a worthwhile read.
Creating Effective Prompts With Copilot
After setting the context, it's time to guide GitHub Copilot's AI powered capabilities to accomplish the task. This process resembles crafting a recipe, where you break down the entire process into smaller, manageable steps. It's not about writing a verbose paragraph describing the end product, but more about articulating the path leading to it.
To get the most out of GitHub Copilot, let it generate code after each step. This approach allows you to review, modify, or accept the code before moving to the next instruction. This step-by-step guidance can ensure the AI stays on the right path, improving the overall efficiency of your programming session.
Just like humans, AI benefits significantly from examples. By providing a sample of what you want, you give GitHub Copilot a clearer vision of your goal. For instance, if you wish to extract specific data from an array, showing an example of the desired outcome can guide GitHub Copilot more effectively.
However, not providing an example might lead to errors or inefficiencies. On the other hand, a clear example can not only prevent such issues but also bring you closer to your desired outcome. It's a simple yet highly effective practice that can enhance the quality of the output.
In the realm of machine learning, we use terms like zero-shot learning, one-shot learning, and few-shot learning to describe how an AI model is trained:
Zero-shot learning involves exposing the model to new scenarios without specific training examples. The model makes predictions based on its training, much like an unsupervised child learning from their surroundings.
One-shot learning is when the model learns from a very limited number of examples. It's as if we've given some initial guidance and are now letting it explore on its own.
Few-shot learning, on the other hand, can be thought of as meticulous training. The model is provided with a few examples and trained to achieve high precision. It's akin to being taught in a highly controlled environment where every step is monitored and corrected.
In the case of GitHub Copilot, it's a bit of each. It uses zero-shot learning to generate code without explicit instruction, one-shot learning to adapt to user styles with minimal examples, and few-shot learning to refine its predictions over time, based on more extensive user interaction.
Consider this comparison:
Without specific guidance, Prompt:
#Fetch the current date and time in Python
from datetime import datetime
current_datetime = datetime.now()
print(current_datetime)